This article was co-written with Grammarly engineer Oleksii Sliusarenko.
At Grammarly, we use a lot of off-the-shelf core NLP technologies to help us make a little bit of sense of the mess that is natural language texts (English in particular). The issue with all these technologies is that even small errors in their output are often multiplied by downstream algorithms. So when a sophisticated mistake-detection algorithm is supposed to work on individual sentences but receives a fragment of a sentence or a couple merged together, it may find all sorts of funny things inside.
In this post, we analyze the problem of sentence splitting for English texts and evaluate some of the approaches to solving it. As usual, good data is key, and we discuss how we use OntoNotes and MASC corpora for this task.
The problem at hand
At first glance, it may seem that sentence splitting is relatively easy by NLP standards. What could be easier than finding closing punctuation marks and splitting based on them? But look closer: If you consider all the various corner cases—like unknown abbreviations, different email addresses, as well as different styles of punctuation inside quotation marks—you may not be so sure.
Here are some of the peculiar examples.
| EXAMPLE | DESCRIPTION |
|---|---|
He adds, in a far less amused tone, that the government has been talking about making Mt. Kuanyin a national park for a long time, and has banned construction or use of the mountain. |
Names after abbreviation, no split |
The luxury auto maker last year sold 1,214 cars in the U.S. Howard Mosher, president and chief executive officer, said he anticipates growth for the luxury auto maker in Britain and Europe, and in Far Eastern markets. |
Names after abbreviation, split |
The JW considers itself THE kingdom of God on earth. (‘Kindom Hall’) So it is only to be expected that they do not see a reason to run to and report everything to the government. |
Nonstandard sentence ends (parentheses) |
A larger list is provided under the Evaluation section.
Existing tools
As sentence splitting is at the core of many NLP activities, it is provided by most NLP frameworks and libraries. We use Java tools for doing this kind of basic processing, so we were interested first and foremost in the Java libraries, and here are a few that we’ve found:
- OpenNLP
- Stanford CoreNLP
- GATE
- NLTK
- splitta
- LingPipe
- University of Illinois Sentence Segmentation tool
They are based on three main approaches:
- statistical inference (e.g., logistic regression in OpenNLP)
- regex-based rules (GATE)
- first tokenizing using finite automata and then sentence splitting (Stanford CoreNLP)
For the purposes of this article, we’ll use the OpenNLP sentence splitter (as the one that can be rather easily controlled) and try to get its quality to the maximum possible level with some additional post-processing.
Evaluation
We have accumulated a lot of interesting fail cases of our sentence splitter and wanted to see how other systems deal with them. Also, we wanted to improve the splitter that we use—or take the best parts of other tools if they are better in some aspects. The main parameter for us was quality. Speed was not so important because the next steps of text processing take orders of magnitude more time, in any case.
To perform a reliable evaluation, you need to have a reliable dataset in terms of size, quality (i.e., manually annotated), and coverage of different genres of text and writing styles, along with a statistically valid distribution of samples. There’s no ideal candidate here, but of the existing corpora we’re aware of, we’ve found OntoNotes 4 and MASC to be the most adequate for this task. To be sure, they have their problems and deficiencies–but overall, they are good enough.
First of all, here are the results of evaluating these two corpora:
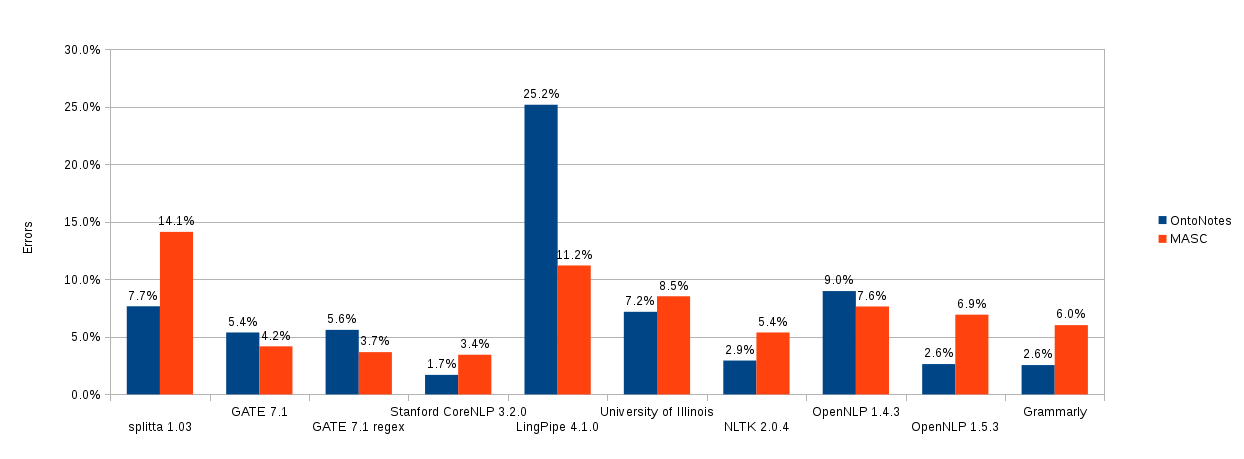
Traditional metrics for sentence-splitting quality are the same as for any classification problem: precision and recall. For this evaluation, though, a simpler method was chosen—the number of sentences that were not split correctly. After observing some fail cases of sentence splitters, this metric was changed to be more robust; before counting the number of failed sentences, all non-alphanumeric characters were deleted. So, for example, for cases with quotes, both splits by periods or by quote marks were treated as valid.
Only 30% of the OntoNotes corpus was used for evaluation, as the remaining 70% was reserved for training.
Error analysis
Why are the results different? Manual examination of the fail cases has shown the following:
- The MASC corpus has a lot of mistakes. This fact explains why the results for the MASC corpus are worse than for OntoNotes. Therefore, MASC is only good as a secondary source of evaluation.
- The MASC corpus has more modern special cases, such as URLs, emails, HTML formatting, citations, etc.
- There are many nontrivial cases, so the quality depends a lot on the training dataset and number of features used for the model.
Here is a list of the most common difficult cases:
| EXAMPLE | DESCRIPTION |
|---|---|
At some schools, even professionals boasting Ph.D. degrees are coming back to school for Master’s degrees. |
Small letter after dot, no split |
If Harvard doesn’t come through, I ‘ll take the test to get into Yale. many parents set goals for their children, or maybe they don’t set a goal. |
Small letter after dot, split (manual mistakes/informal text) |
He adds, in a far less amused tone, that the government has been talking about making Mt. Kuanyin a national park for a long time, and has banned construction or use of the mountain. |
Names after abbreviation, no split |
The luxury auto maker last year sold 1,214 cars in the U.S. Howard Mosher, president and chief executive officer, said he anticipates growth for the luxury auto maker in Britain and Europe, and in Far Eastern markets. |
Names after abbreviation, split |
No, to my mind, the Journal did not “defend sleaze, fraud, waste, embezzlement, influence-peddling and abuse of the public trust...” it defended appropriate constitutional safeguards and practical common sense. |
Ellipsis, split |
After seeing the list of what would not be open and/or on duty... which I’m also quite sure is not complete... I ‘ll go out on a limb.... and predict... that this will not happen. |
Ellipsis, no split |
Bharat Ratna Avul Pakir Jainulabdeen Abdul Kalam is also called as Dr. A.P.J Abdul Kalam. |
Initials, no split |
The agency said it confirmed American Continental’s preferred stock rating at C. American Continental’s thrift unit, Los Angeles-based Lincoln Savings & Loan Association, is in receivership and the parent company has filed for protection from creditor lawsuits under Chapter 11 of the federal Bankruptcy Code. |
Looks like initials, split |
Wang first asked: “Are you sure you want the original inscription ground off?” Without thinking twice about it, Huang said yes. |
Quotes, split |
“It’s too much, there’s only us two, how are we going to eat this?” I asked young Zhao as I looked at him in surprise. |
Quotes, no split |
The JW considers itself THE kingdom of God on earth. (‘Kindom Hall’) So it is only to be expected that they do not see a reason to run to and report everything to the government. |
Nonstandard sentence ends (parentheses) |
Everyone please note my blog on Donews http://blog.donews.com/pangshengdong. What I say is not necessarily right, but I am confident that if you read it carefully it should give you a start. |
URL |
Improving off-the-shelf performance
The advantage of statistics-based systems is that they may get better with better training sets. Most of the software we’ve examined is trained on the Penn TreeBank. It has well-known issues with size, coverage, and modernity. The rule of thumb is to consider the Penn Treebank–trained systems only as example systems; to get the best results, it is necessary to retrain them on a more adequate dataset for the domain.
Here are the results of improving the splitter step-by-step:
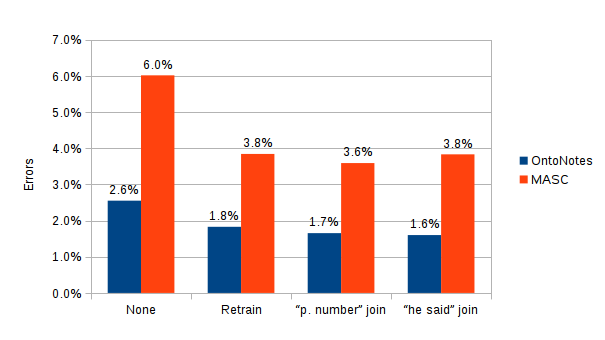
The improvement steps were the following:
- 70% of the OntoNotes corpus was used to retrain the OpenNLP splitter.
- During post-processing, if one sentence ends with “p.” and the next one begins with a number, then these sentences are joined together.
- During post-processing, if one sentence ends with a question or exclamation mark followed by a double quote, and the other sentence begins with a lower case letter, then these sentences are joined together.
- Finally, other small tweaks were added (like “e.g.” and “i.e.” joining), but this produced a less noticeable effect.
We may notice again that the MASC corpus has problems with incorrect annotations because after the “he said” improvement the error rate increased on the MASC corpus, while manual observation shows that the real quality has improved. So let us see the final comparison by testing 30% of the OntoNotes corpus:
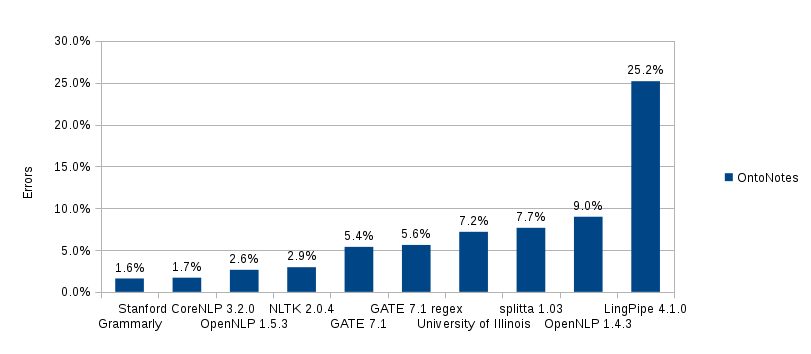
Finally, note that some factors were not taken into account in this graph, for example:
- Some of the splitters might have used in OntoNotes for training, so their score may be artificially good.
- The final (after this comparison) model of the splitter may be retrained on the whole OntoNotes corpus. This should improve the eventual accuracy even further.
Is sentence splitting solved?
The performance we were able to get in our evaluation is fairly good: a 1.6% error rate, which represents a decrease in error rate of more than 60% compared to the original OpenNLP variant. If you look at it from a human standpoint, with what accuracy are we able to split sentences? I think that 99,95% is not too far off. How can we get there for a computer system? One approach may be adding more hand-crafted rules. The other one is using special algorithms (sentence parsing or language models) for hard cases like abbreviations followed by proper nouns.
Finally, we didn’t consider the case of splitting sentences in the absence of punctuation marks. First of all, this is a relatively difficult case, and secondly, for us, it’s an error that we expect our algorithms to detect in later stages of processing.